10. NumPy, Pandas a Matplotlib
Obsah
Všechny tyto balíčky je nutné doinstalovat pomocí pip.
Knihovna NumPy
NumPy (z Numerical Python) je jedna z klíčových knihoven pro vědecké výpočty a datovou analýzu v Pythonu, protože poskytuje podporu pro práci s velkými vícerozměrnými poli a maticemi. Více informací najdete zde.
Proč používat Numpy namísto standardních datových typů
- Výkon: NumPy je implementováno v jazyce C, který je mnohem rychlejší než nativní Python.
- Nižší paměťová náročnost: NumPy používá méně paměti, protože její pole jsou uložena jako homogenní datové struktury (všechny prvky mají stejný typ), zatímco standardní Python seznamy mohou obsahovat prvky různých typů, což je méně efektivní z hlediska paměti.
- Jednodušší a čitelnější kód: NumPy umožňuje vektorizaci operací, což znamená, že můžete provádět operace na celých polích najednou bez nutnosti psát cykly.
- Velké objemy dat: NumPy je optimalizováno pro práci s velkými daty, což je důležité například při jejich analýze nebo strojovém učení.
Vytvoření a inicializace polí
Více najdete zde
import numpy as np
# vytvoření pole ze seznamu
a1D = np.array([1, 2, 3, 4])
a2D = np.array([[1, 2], [3, 4]])
a3D = np.array([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
# tvar pole
a1D.shape # (4,)
a2D.shape # (2, 2)
a3D.shape # (2, 2, 2)
# dimenze pole
a1D.ndim # 1
a2D.ndim # 2
a3D.ndim # 3
# pole s datovým type signed int s 8 bity (rozsah -128 až 127)
a_int8 = np.array([42, 54, 65], dtype=np.int8)
# pole s datovým type unsigned int s 32 bity
a_uint32 = np.array([2, 3, 4], dtype=np.uint32)
# OverflowError: Python integer 128 out of bounds for int8
np.array([127, 128, 129], dtype=np.int8)
# vyvoření pole pomocí funkce arange
np.arange(10)
# array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
np.arange(2, 10, dtype=float)
# array([2., 3., 4., 5., 6., 7., 8., 9.])
np.arange(2, 3, 0.1)
# array([2. , 2.1, 2.2, 2.3, 2.4, 2.5, 2.6, 2.7, 2.8, 2.9])
## Další užitečné inicializační funkce
np.zeros((2,3))
# array([[0., 0., 0.],
# [0., 0., 0.]])
np.ones((4,2,2), dtype='int32')
# array([[1, 1],
# [1, 1]])
np.full((2,2), 42)
# array([[42, 42],
# [42, 42]])
np.random.rand(1,4)
# array([[0.56742422, 0.9394484 , 0.79633715, 0.04484392]])
np.identity(3)
# array([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
np.repeat(a1D, 3, axis=0)
# array([1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4])
np.repeat([a1D], 3, axis=0)
# array([[1, 2, 3, 4],
# [1, 2, 3, 4],
# [1, 2, 3, 4]])
Základy práce s poli
import numpy as np
a = np.array([[1, 2, 3], [4, 5, 6]])
# array([[1 2 3]
# [4 5 6]])
a[1, 2]
# np.int64(6)
a[1, 2] = 42
# array([[ 1, 2, 3],
# [ 4, 5, 42]])
a[0, :]
# array([1, 2, 3])
a[:, 1]
# array([2, 5])
a[:, 1] = [5, 2]
# array([[ 1, 5, 3],
# [ 4, 2, 42]])
# vytvoření pole masky
(a > 1) & (a < 5)
# array([[False, False, True],
# [ True, True, False]])
# změna tvaru a spojování
a.reshape(1, 6)
# array([[ 1, 5, 3, 4, 2, 42]])
a.reshape(3, 2)
# array([[ 1, 5],
# [ 3, 4],
# [ 2, 42]])
np.vstack([a, [0, 0, 0], a])
# array([[ 1, 5, 3],
# [ 4, 2, 42],
# [ 0, 0, 0],
# [ 1, 5, 3],
# [ 4, 2, 42]])
np.hstack([a, [[0], [0]], a])
# array([[ 1, 5, 3, 0, 1, 5, 3],
# [ 4, 2, 42, 0, 4, 2, 42]])
Matematické operace s poli
import numpy as np
a = np.array([1, 2, 3])
b = np.array([4, 5, 6])
a + 3
# array([4, 5, 6])
a - 3
# array([-2, -1, 0])
a * 3
# array([3, 6, 9])
a / 3
# array([0.33333333, 0.66666667, 1. ])
a ** 3
# array([ 1, 8, 27])
a + b
# array([5, 7, 9])
a * b
# array([ 4, 10, 18])
# násobení matic
m1 = np.ones((2, 3))
m2 = np.full((3, 2), 3)
np.matmul(m1, m2)
# array([[9., 9.],
# [9., 9.]])
m3 = np.array([[1, 2, 3],[4, 5, 6]])
np.min(m3)
# np.int64(1)
np.max(m3, axis=1)
# array([3, 6])
np.sum(m3, axis=0)
# array([5, 7, 9])
Pandas
Pandas je populární knihovna pro práci s tabulkovými daty (podobnými Excelu nebo databázovým tabulkám) a umožňuje snadné provádění složitých analýz a úprav dat. Více naleznete zde.
Pro efektivní práci s daty Pandas využívá NumPy tak, že data v DataFrame a Series jsou uložena ve formě NumPy polí.
Pandas je také inspirací pro balíček Data, který jste programovali v rámci úkolů H04 až H07 (v rámci úkolu ale bylo potřeba některé metody a jejich pojmenování změnit).
Pro následující příklady uvažujme soubor data.csv s tímto obsahem:
Activity,Duration,Pulse,Maxpulse,Calories
Running,60,110,130,409.1
Swimming,45,90,112,
Running,60,98,120,215.2
Running,60,100,120,300.0
Running,60,103,123,323.0
Walking,210,137,184,1860.4
Swimming,45,104,129,266.0
Swimming,45,90,112,180.1
Swimming,45,107,137,
Yoga,30,90,107,105.3
Načtení dat
Hlavní datový typ používaný v Pandas je DataFrame, tedy dvourozměrná datová struktura podobná tabulce (řádky a sloupce). Načtení dat pomocí read_csv() nebo read_xlsx() vytvoří tabulku právě v instanci DataFrame.
import pandas as pd
# načtení klasického csv
df = pd.read_csv('data.csv')
# uložení DataFrame do csv
new_df.to_csv('new_data.csv')
# head vrátí prvních n řadků
print(df.head(3))
# Activity Duration Pulse Maxpulse Calories
# 0 Running 60 110 130 409.1
# 1 Swimming 45 90 112 NaN
# 2 Running 60 98 120 215.2
# další zpsůsoby načtení souoru
# načtení cvs, kde oddělovačem je tabulátor
df = pd.read_csv('data.txt', delimiter='\t')
# načtení formátu z excelu
df_xlsx = pd.read_excel('data.xlsx')
Základní operace
Jednotlivé sloupce jsou uloženy v instancích třídy Series.
import pandas as pd
df = pd.read_csv('data.csv')
# vrací objekt Index, tedy hlavičku tabulky
df.columns
# Index(['Activity', 'Duration', 'Pulse', 'Maxpulse', 'Calories'], dtype='object')
# Series s názvem 'Activity'
df['Activity']
# 0 Running
# 1 Swimming
# ...
# 9 Yoga
# Name: Activity, dtype: object
# vrátí DataFrame jen se sloupci 'Pulse' a 'Calories'
df[['Pulse', 'Calories']]
# Pulse Calories
# 0 110 409.1
# 1 98 215.2
# 2 100 300.0
# ...
# přímé indexování do DataFrame
df.iloc[0,0]
# 'Running'
df.iloc[0,4]
# np.float64(409.1)
# iterace přes hlavičku DataFrame
for label in df:
print(label)
# Activity
# Duration
# ...
# iterace přes řádky - row je instance Series
for index, row in df.iterrows():
print(f"{index} {row['Activity']}: {row['Calories']} calories")
# 0 Running: 409.1 calories
# 1 Swimming: nan calories
# 2 Running: 215.2 calories
# ...
Modifikace a filtrování dat
import pandas as pd
df = pd.read_csv('data.csv')
# setřízení podle sloupce 'Activity' vzestupně a podle' Calories' sestupně
new_df = df.sort_values(['Activity', 'Calories'], ascending=[1,0])
# Activity Duration Pulse Maxpulse Calories
# 0 Running 60 110 130 409.1
# 4 Running 60 103 123 323.0
# 3 Running 60 100 120 300.0
# 2 Running 60 98 120 215.2
# 6 Swimming 45 104 129 266.0
# ...
# index výsledného DataFrame new_df není po setřízení dat korektní, proto jej resetujeme
# 'drop' odstraní původní index
# 'inplace' provede operaci přímo na new_df bez vytvoření nové instance
new_df.reset_index(drop=True, inplace=True)
# Activity Duration Pulse Maxpulse Calories
# 0 Running 60 110 130 409.1
# 1 Running 60 103 123 323.0
# 2 Running 60 100 120 300.0
# 3 Running 60 98 120 215.2
# 4 Swimming 45 104 129 266.0
# ...
# přidání nového sloupce
new_df['CalsPerMin'] = df["Calories"] / df["Duration"]
# Activity Duration Pulse Maxpulse Calories CalsPerMin
# 0 Running 60 110 130 409.1 6.818333
# 1 Running 60 103 123 323.0 NaN
# 2 Running 60 100 120 300.0 3.586667
# změna pořadí sloupců v původní DataFrame
cols = list(df.columns)
df[[cols[0]] + cols[4:] + cols[1:4]]
# Activity Calories Duration Pulse Maxpulse
# 0 Running 409.1 60 110 130
# 1 Swimming NaN 45 90 112
# ...
# filtrování řádků - výsldek je DataFrame s řádky, které mají 'Activity' rovno 'Swimming'
df.loc[df['Activity'] == "Swimming"]
# Activity Duration Pulse Maxpulse Calories
# 1 Swimming 45 90 112 NaN
# 6 Swimming 45 104 129 266.0
# 7 Swimming 45 90 112 180.1
# 8 Swimming 45 107 137 NaN
# komplexní podmínka s použitím & (log. and) a | (log. or)
df.loc[((df['Activity'] == 'Running') | (df['Activity'] == 'Swimming')) & (df['Calories'] > 250)]
# Activity Duration Pulse Maxpulse Calories
# 0 Running 60 110 130 409.1
# 3 Running 60 100 120 300.0
# 4 Running 60 103 123 323.0
# 6 Swimming 45 104 129 266.0
# použití metody isin(), logické negace ~ a metody isna() pro detekci NaN
df.loc[df['Activity'].isin(['Running', 'Swimming']) & ~df['Calories'].isna()]
# Activity Duration Pulse Maxpulse Calories
# 0 Running 60 110 130 409.1
# 2 Running 60 98 120 215.2
# 3 Running 60 100 120 300.0
# 4 Running 60 103 123 323.0
# 6 Swimming 45 104 129 266.0
# 7 Swimming 45 90 112 180.1
# podmíněné nahrazení všech NaN v 'Calories' za 0, isna() testuje jestli je hodnota NaN
df.loc[df['Calories'].isna(), 'Calories'] = 0
# Activity Duration Pulse Maxpulse Calories CalsPerMin
# 0 Running 60 110 130 409.1 170
# 1 Swimming 45 90 112 0.0 135
# 2 Running 60 98 120 215.2 158
# opět nahrazení NaN hodnot za 0 pomocí metody fillna()
df = df.fillna(0)
Agregace hodnot
Pro agregaci hodnot ve sloupcích má instance Series dispozici například metody .sum() nebo .count(). Složitější agregace pak lze udělat pomocí .groupby(), který agreguje přes všechny řádky se stejnou hodotou pro daný sloupec (například sečte všechny kalorie v rámci jednotlivých sportů).
import pandas as pd
df = pd.read_csv('data.csv')
# Series se součtem všech 'Duration' a 'Calories'
df.iloc[:, [1,4]].sum()
# Duration 660.0
# Calories 3659.1
# dtype: float64
# DataFrame průměrných hodnot pro jednotlivé aktivity
df.groupby("Activity").mean(numeric_only=True)
# Duration Pulse Maxpulse Calories
# Activity
# Running 60.0 102.75 123.25 311.825
# Swimming 45.0 97.75 122.50 111.525
# Walking 210.0 137.00 184.00 1860.400
# Yoga 30.0 90.00 107.00 105.300
# Series se součtem kalorií pro každou aktivitu
df.groupby("Activity").sum()["Calories"]
# Activity
# Running 1247.3
# Swimming 446.1
# Walking 1860.4
# Yoga 105.3
# Name: Calories, dtype: float64
Matplotlib
Matplotlib je populární knihovna pro vytváření grafů a vizualizací dat. Používá se především k vytváření dvourozměrných grafů, jako jsou čárové grafy, sloupcové grafy, histogramy, scatter ploty, boxploty a další. Díky své flexibilitě umožňuje přizpůsobit prakticky každý aspekt grafu. Více naleznete zde.
Nejčastěji používaný modul je pyplot, který funguje podobně jako příkazy v aplikacích pro kreslení grafů (například MATLAB), funguje dobře s knihovnami jako NumPy, Pandas nebo SciPy (knihovna pro vědecké/fyzikální výpočty), takže je vhodný pro analýzu dat. Vytvořené grafy lze snadno exportovat do různých formátů, například PNG, PDF nebo SVG.
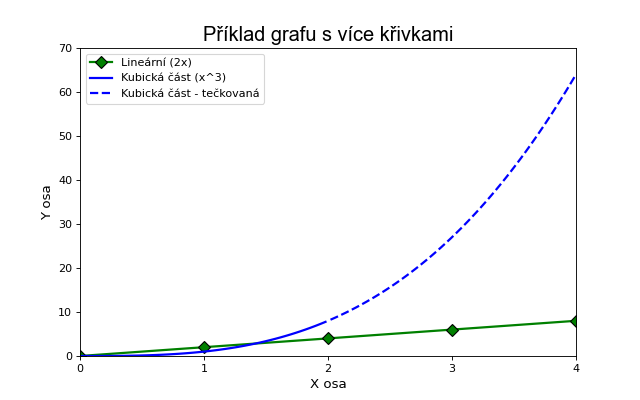
Základní graf
Pro vytvoření základních grafů slouží funkce plot(). Všechny příkazy modifikují tentýž graf, dokud nedojde k resetu/zavření kreslícího prostředí pomocí funkcí clf() (odstraní obsah aktuálního grafu, ale zachová nastavení jako velikost grafu nebo DPI) nebo close() (odstraní celý graf).
import numpy as np
import matplotlib.pyplot as plt
# data
x = [0, 1, 2, 3, 4]
y = [0, 2, 4, 6, 8]
# nastavení velikosti grafu a DPI
plt.figure(figsize=(8, 5), dpi=80)
# křivka 1
# Použití stylu fmt (barva, značka, čára), tj. 'gD-' je zelená křivka zelené barvy ('g'),
# body jsou v diamantovém tvaru ('D') a je vykreslená plnou čárou ('-')
plt.plot(x, y, 'gD-', label='Lineární (2x)', linewidth=2, markersize=8, markeredgecolor='black')
# křivka 2
x2 = np.linspace(0, 4, 100)
y2 = x2**3
# rozdělení křivky na pevnou čáru a tečkovanou část
plt.plot(x2[x2 <= 2], y2[x2 <= 2], 'b-', label='Kubická část (x^3)', linewidth=2)
plt.plot(x2[x2 > 2], y2[x2 > 2], 'b--', label='Kubická část - tečkovaná', linewidth=2)
# titulek a popisky os
plt.title('Příklad grafu s více křivkami', fontdict={'fontname': 'Arial', 'fontsize': 18})
plt.xlabel('X osa', fontsize=12)
plt.ylabel('Y osa', fontsize=12)
# nastavení rozsahu osy X a Y
plt.xlim(0, 4)
plt.ylim(0, 70)
# nastavení značek na ose X a Y
plt.xticks([0, 1, 2, 3, 4])
plt.yticks(range(0, 80, 10))
# legenda
plt.legend()
# uložení do souboru
plt.savefig("some_path/graph.png", dpi=300)
# zobrazení grafu
plt.show()
# reset prostředí pro kreslení
plt.close()
A výsledný graf:
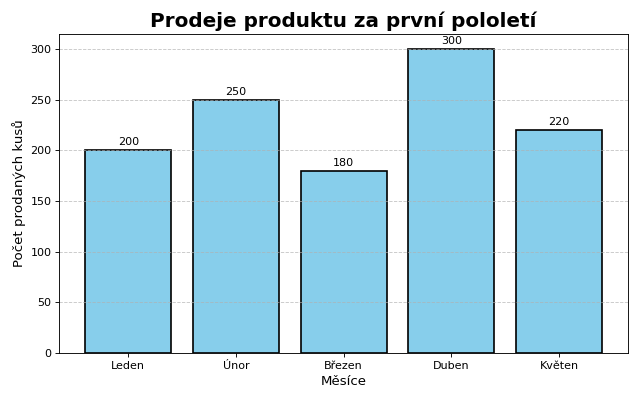
Sloupcový graf
Pro vytvoření základních grafů slouží funkce bar().
import matplotlib.pyplot as plt
# data
months = ['Leden', 'Únor', 'Březen', 'Duben', 'Květen']
sales = [200, 250, 180, 300, 220]
# nastavení velikosti grafu
plt.figure(figsize=(8, 5), dpi=80)
# vykreslení sloupcového grafu
plt.bar(months, sales, color='skyblue', edgecolor='black', linewidth=1.5)
# přidání názvu, popisků os a mřížky
plt.title('Prodeje produktu za první pololetí', fontsize=18, fontweight='bold')
plt.xlabel('Měsíce', fontsize=12)
plt.ylabel('Počet prodaných kusů', fontsize=12)
plt.grid(axis='y', linestyle='--', alpha=0.7)
# přidání hodnot na vrchol sloupců
for i, value in enumerate(sales):
plt.text(i, value + 5, str(value), ha='center', fontsize=10)
# zobrazení grafu
plt.tight_layout() # Zajistí, že graf nebude oříznut
plt.show()
A výsledný sloupcový graf:
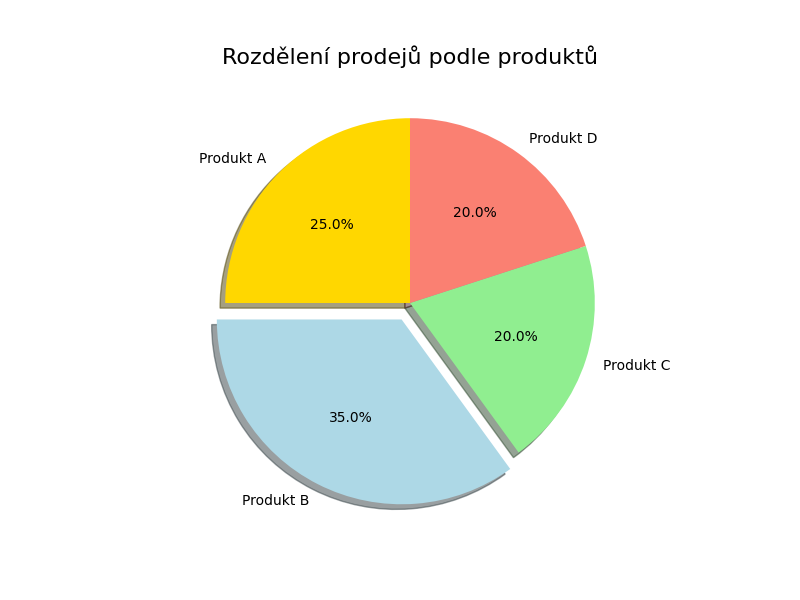
Koláčový graf
Pro vytvoření základních grafů slouží funkce pie().
import matplotlib.pyplot as plt
# data
labels = ['Produkt A', 'Produkt B', 'Produkt C', 'Produkt D']
sizes = [25, 35, 20, 20] # Procentuální podíly
colors = ['gold', 'lightblue', 'lightgreen', 'salmon']
explode = (0, 0.1, 0, 0) # Zvýraznění druhého segmentu
# vytvoření koláčového grafu
plt.figure(figsize=(8, 6))
plt.pie(
sizes,
labels=labels,
colors=colors,
explode=explode,
autopct='%1.1f%%', # Zobrazení procent
startangle=90, # Rotace grafu
shadow=True # Stín pod grafem
)
# přidání názvu
plt.title('Rozdělení prodejů podle produktů', fontsize=16)
# zobrazení grafu
plt.show()
A výsledný koláčový graf:
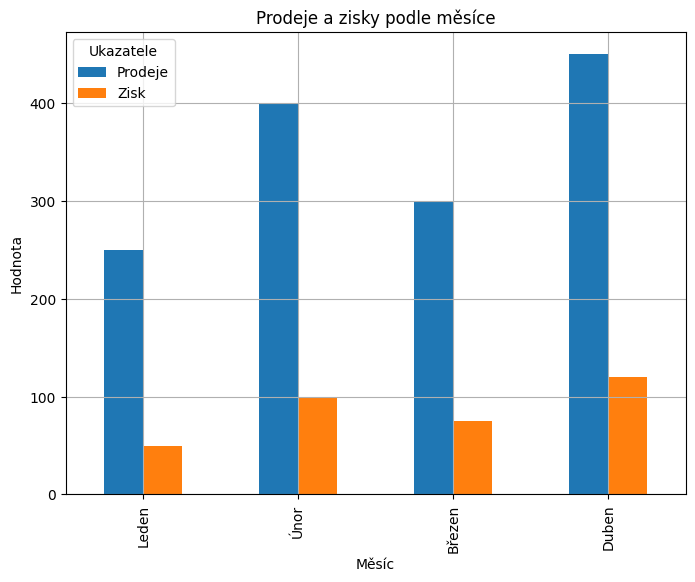
Matplotlib a Pandas
Metoda plot třídy DataFrame je určená pro rychlou vizualizaci dat pomocí matplotlib, kde pomocí parametru kind specifikujete typ grafu.
import pandas as pd
import matplotlib.pyplot as plt
# Vytvoření DataFrame
data = {
'Měsíc': ['Leden', 'Únor', 'Březen', 'Duben'],
'Prodeje': [250, 400, 300, 450],
'Zisk': [50, 100, 75, 120]
}
df = pd.DataFrame(data)
# Vykreslení sloupcového grafu
df.plot(x='Měsíc', y=['Prodeje', 'Zisk'], kind='bar', figsize=(8, 6))
plt.title('Prodeje a zisky podle měsíce')
plt.xlabel('Měsíc')
plt.ylabel('Hodnota')
plt.grid(True)
plt.legend(title='Ukazatele')
plt.show()
A výsledný graf: